Interrupções são eventos (exceto desvios) que mudam o fluxo normal da execução de um programa.
Quando uma interrupção
ocorre durante o processo de execução, o processador deve
parar a execução corrente para tratar a interrupção.
A não ser que a interrupção não devolva o controle
ao processo interrompido (por exemplo, no caso de um crash do sistema),
algumas informações de estado desse processo são salvas,
para que quando terminar o tratamento da interrupção, os
estados dos processos salvos sejam restaurados e o processamento interrompido
seja completado.
A informação
fundamental que deve ser salva sobre um processo, visando restaurar sua
execução em um momento posterior, é o valor do contador
de programa. Na prática, outras informações também
devem ser salvas, mas o contador de programa é essencial pois somente
ele pode definir quais instruções realmente foram executadas
antes da interrupção. Dependendo de quais instruções
foram completadas ou não, quando do tratamento da interrupção,
pode-se classificar as interrupções como precisas
ou imprecisas.
Interrupções precisas
são uma forma de garantir que um sistema com processamento de interrupções
possa continuar a execução correta das instruções,
e para serem classificadas assim devem obedecer às seguintes exigências,
conhecidas como Condições de Interrupções
Precisas de Smith e Pleszkun [SP88]:
O problema das interrupções
precisas existe desde os primeiros processadores com pipeline. O
IBM 360/91 (1967) foi um computador que apresentava interrupções
imprecisas sob certas circunstâncias, como interrupções
de ponto flutuante. Isso devia-se à utilização do
Algoritmo
de Tomasulo para despachar instruções fora de ordem para
múltiplas unidades funcionais, mas sem o suporte necessário
à consistência dessa execução em caso de interrupções.
Modelos subsequentes das linhas IBM
360 e 370 utilizavam pipelines menos agressivos, onde as instruções
processadas somente modificavam o estado do processo na ordem do programa,
tornando suas interrupções precisas.
Outro enfoque às interrupções
imprecisas foi dado pelas máquinas CDC6600 (1970), CDC7600 (1970)
e alguns Cray (1978), que permitiam algumas condições de
interrupções imprecisas, para que o desempenho fosse ampliado
com o despacho fora de seqüência. Assim, apenas as interrupções
realmente críticas eram tratadas precisamente, como por exemplo,
as interrupções de I/O.
Outros computadores, como o CDC STAR-100
e o CYBER 200, para tratar o despacho fora de ordem de modo mais seguro,
utilizavam o invisible exchange package, que era um procedimento
residente na memória e que capturava as informações
de estado da máquina, resultantes das instruções parcialmente
completas.
Foi também sugerido para a
arquitetura MIPS o uso de um "salvador" de pipeline, cuja função
era a de guardar todos estados de um segmento do pipeline, e restaurar
exatamente a partir daquele ponto. Com isso, pôde-se contar com o
despacho fora de seqüência, com as vantagens de interrupções
arquiteturalmente precisas.
O CDC CYBER 180/990 (1984) usava um
history
buffer, onde as informações eram salvas antes de serem
modificadas, e na ocorrência de uma interrupção, as
modificações eram desfeitas.
Tomando por exemplo a execução
das seguintes instruções, em um processador superescalar:
DIV F0, F2, F4
24 ciclos
ADD F10, F10, F8
3 ciclos
SUBF F12, F12, F14
3 ciclos
Supondo que a instrução SUBF gera uma interrupção aritmética, e que a instrução DIVF ainda não terminou sua execução, ocorre uma situação propícia a uma interrupção imprecisa. Para tratar essa situação, certas escolhas devem ser realizadas, e suas principais vantagens e desvantagens são citadas abaixo:
Ignorar - esta opção
não pode ser descartada, mas tem grandes restrições
para sua implementação em um sistema comercial. Sua principal
vantagem é que provê um tratamento simples e que possibilita
alta performance dos sistemas. No entanto, pode não ser possível
relacionar uma interrupção à uma instrução
específica, ocorrendo então erros de inacuidade, no resultado
final.
Armazenar os resultados das operações
anteriores - Tem como desvantagem a necessidade de grandes buffers
de armazenamento, e a necessidade de uma grande complexidade adicional
ao hardware do processador.
Implementar interrupções
"quase" precisas - Essas interrupções têm alguma
forma de salvamento de contexto associado, de maneira que o tratamento
das interrupções gera uma seqüência de interrupções
precisas.
Determinar se as interrupções
imprecisas podem ser "adiadas" no pipeline - Dessa foram, a
realocação das instruções ou das interrupções
geradas por elas podem ser colocadas em uma fila de espera, de forma que
o ordem de execução é mantida, sem a necessidade de
tratar certas interrupções durante a execução
de outras instruções.
Para implementar interrupções
precisas, o estado do processador deve estar serialmente correto
antes que esse estado possa ser salvo, e o tratamento da interrupção
iniciado. Existem duas formas de serializar um estado.
O método mais fácil,
mas que apresenta sérias desvantagens para o uso em processadores
superescalares, utiliza o princípio de não permitir que
o estado torne-se serialmente incorreto. Esse controle exige que as
instruções sejam processadas na ordem, e que somente após
o estado de uma instrução ser salvo, outra instrução
pode ser executada.
A segunda técnica utiliza o
princípio de corrigir o estado, caso seja serialmente incorreto.
Essa técnica envolve a adição de estratégias
específicas para o tratamento das interrupções. Sua
grande vantagem é que pode trabalhar independentemente da ordem
de execução e finalização das instruções,
e mesmo sobre as instruções despachadas após a interrupção
ter causado a mudança do estado do processador.
Essas técnicas de processamento
de interrupções em hardware geralmente afetam apenas
o estado do processador, porque o estado de um dispositivo externo raramente
necessita modificações, para assegurar a retomada do processamento.
Em um processador que permite interrupções,
o sistema de tratamento salva dados suficientes do processo, para garantir
a recuperação após uma interrupção.
Esses dados normalmente podem ser salvos em dois locais diferentes: a parte
do processo que não faz parte das informações pertinentes
ao processador são salvas pelo sistema operacional, e o estado do
processador é salvo diretamente pelo processador, de acordo com
a estratégia adotada em hardware. A eficiência do tratamento
dessas interrupções depende também da freqüência
e da quantidade de dados do processo que serão salvos, bem como
o local de armazenamento.
Da necessidade de balancear a freqüência
e a quantidade de dados do estado do processo a serem salvos, existem dois
grandes ramos de implementação do tratamento das interrupções.
A primeira forma consiste apenas em
salvar o estado do processo. Já a segunda, que primeiro serializa
o estado e após salva-o, é a mais usada nos processadores
comerciais. Embora em teoria a etapa de serialização possa
ser descartada caso hajam dados suficientes dos processos salvos, o aumento
de latência do processamento das interrupções aumenta
muito com um salvamento tão massivo de dados.
5.1 - Hardware para Serialização dos Estados:
Arquitetura - Uma das mais simples
maneiras de produzir um hardware serializador é através
da própria arquitetura do processador. Isto é obtido ao projetar
o sistema de forma que todas as instruções sejam completadas
serialmente, e que não causem nenhuma mudança de estado que
precise ser desfeita, devido a interrupções.
Realimentação do
pipeline
(Result Shift Register) - Nessa técnica, as instruções
são reenviadas à fila de execução, se necessário,
para assegurar que as mudanças no estado do processador ocorram
serialmente. Como nenhuma instrução é validada antes
que o processador tenha certeza que essa instrução não
causa nenhuma interrupção, não existem mudanças
no estado do processador para serem desfeitas.
Buffer de Reordenamento - Nessa
implementação, uma área especial da memória
recebe o resultado das instruções que são executadas.
É permitida a entrada de resultados de instruções
executadas fora de ordem, mas somente serão validadas seqüencialmente,
à medida em que ficam disponíveis, e somente após
o processador ter certeza que não causarão interrupções.
Unidade de Atualização
de Registradores - Esta unidade reordena os resultados das instruções
de forma seqüencial, como o Buffer de Reordenamento. Esta técnica
também resolve dependências através de uma versão
estendida do Algoritmo de Tomasulo.
Buffer de History - Nessa implementação,
uma área especial da memória guarda as informações
antigas, relativas ao estado do processador, e à medida em que esse
estado é alterado, as novas informações substituem
as antigas. Assim, se uma interrupção ocorrer, o estado imediatamente
anterior ao da interrupção é relido, e restaura o
estado do processador.
Arquivo Futuro - Nessa técnica
existem dois arquivos de registro: um é o arquivo futuro,
que é atualizado constantemente com a operação do
processador, e o outro é o arquivo estrutural, atualizado
em ordem pelo buffer de reordenamento. Quando uma interrupção
ocorre, o arquivo estrutural é copiado sobre o arquivo futuro, fazendo
a recuperação do estado do processador no mais adjacente
ponto serialmente correto antes da interrupção.
5.2 - Hardware para salvamento de Estados:
Pilhas - é o método
mais usual, pois basta uma simples pilha na memória, onde o contador
de programa e alguns dados associados são salvos, quando há
uma interrupção. Como o acesso á memória externa
é relativamente lente, somente o contador de programa e alguns poucos
registradores são salvos.
Registradores Shadow
- Ao utilizar registradores shadow, têm-se uma correlação
entre alguns registradores normais e suas sombras. Assim, quando um registrador
normal tem seu estado alterado, a sua sombra também é atualizada,
e no caso de uma interrupção, o estado normal pode ser restaurado
com os dados do registrador shadow. Para garantir a correta relação
dos dados, somente uma instrução tem acesso para modificar
o conteúdo desses registradores sombra, se o processador assegurar
que a instrução não causará uma interrupção.
Sua aplicação pode ser
estendida, de forma que possa ser imaginado um registrado shadow para cada
registrador existente. Embora seja pouco provável que exista uma
máquina que salve seu estado de forma tão abrangente, o uso
dessa forma estendida é notavelmente interessante ao uso com processadores
superescalares, ou quaisquer outros processadores que apresentam situações
difíceis para a serialização.
A desvantagem dessa técnica
é que devido à necessidade de tantos registradores adicionais
e ao hardware de controle necessário, pode-se levar a um
superdimensionamento do processador.
Pilhas Shadow - Sua
função é semelhante aos registradores shadow, exceto
que aqui cada registrador possui sua pilha "sombra". Dessa forma, é
possível armazenar mais de um estado, podendo ser tratadas interrupções
aninhadas.
Hardware de Checkpoint - Esse
método salva periodicamente o estado dos dispositivos externos,
para o tratamento das interrupções. Como a quantidade de
dados pode ser grande, normalmente esses estados são salvos em memória
primária ou secundária.
Processador Auxiliar - É
a implementação de um processador auxiliar, que trata as
interrupções enquanto o processador principal espera (no
caso de interrupções internas) ou continua processando (interrupções
externas). O salvamento de estados ocorre de forma transparente, pois o
processador principal não precisa descartar seus estados para tratar
a excessão. Essa implementação é equivalente
à técnica de registradores shadow estendidos.
As fases do tratamento de
uma situação de interrupção podem ser organizadas
em 6 níveis. As técnicas escolhidas para cada nível
não são independentes, pois as escolhas delimitam o que pode
ser feito nas próximas fases:
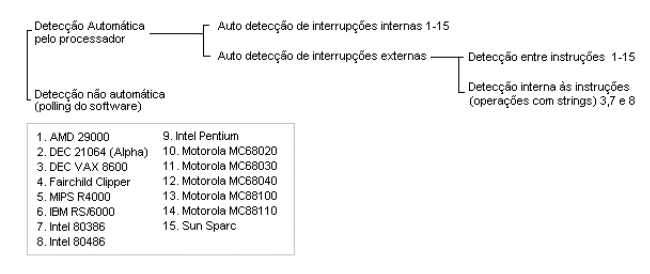
A detecção
de uma interrupção pode ser classificada em dois grandes
ramos: interrupções "internas" às instruções
ou "externas". Interrupções internas significam que uma interrupção
pode ser detectada enquanto a instrução ainda está
dentro do estágio atual do pipeline, por exemplo, interrupções
de falta de página. Já as interrupções externas,
entretanto, normalmente são detectadas somente após o avanço
do estágio do pipeline, ou seja, entre instruções,
como no caso de acesso a dispositivos periféricos.
Aqui,
ou o processador finaliza as instruções pendentes (instruções
despachadas antes da interrupção) ou não faz nada.
Se o processo interrompido não for restaurado, as instruções
pendentes podem ser descartadas.

Nesta
fase, o processador desfaz quaiquer mudanças do estado que foram
causadas por instruções que deveriam se completamente não
executadas, segundo a segunda condição de Smith e Pleszkun.
Se o processador não deseja implementar interrupções
precisas, essa fase é desnecessária.
Em certos casos, alguns processadores somente desfazem parcialmente as
mudanças de estado, e há duas razões possíveis
para isso: o processador pode não requerer que as interrupções
sejam inteiramente precisas para que sua reinicialização
seja correta; ou o processo interrompido não pode (ou não
consegue) ser restaurado.
As fases 2 e 3 compreendem as operações de serialização
do estado.
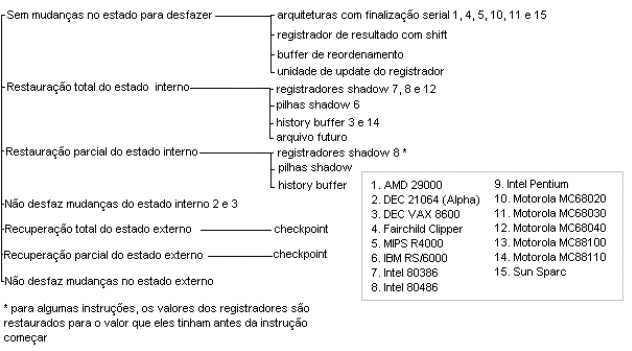
Aqui
o processador salva o estado que será restaurado na fase 6. O salvamento
ocorre após a finalização das instruções
da fase 2 e a correção do estado da fase 3. O contador de
programa salvo nessa fase normalemnte aponta para a primeira instrução
que será carregada no processador após o tratamento da interrupção,
mas pode variar de acordo com as implementações.
Conforme a figura abaixo, cerca de metade dos processadores analisados
usam pilhas para o salvamento do estado. Isso deve-se ao processamento
das fases anteriores, onde o estado do processo já foi serializado,
e não restaram muitas informações para serem salvas.

Nessa fase são executadas duas tarefas: Identificar o código
adequado para tratar a interrupção e rodá-lo. Algumas
interrupções (por exemplo, faltas de página) podem
ser projetadas para não exigir um tratamento de interrupção
em software. Para isso, deve existir um hardware ou microcódigo
especializado.
Outra alternativa são os vetores de interrupções,
onde ponteiros para os códigos de tratamento são armazenados
em uma tabela acessível ao processador quando a interrupção
ocorre. Um hardware especial identifica a causa da interrupção
e carrega o endereço adequado no contador de programa.
O sistema de registrador de interrupção funciona de forma
que o dispositivo que gerou a interrupção seta seu código
de identificação nesse registrador, para a posterior ação
de tratamento.
Outra alternativa, para interrupções externas, é o
polling
de software. Quando há uma interrupção, o sistema
de polling é ativado, e vai buscar nos dispositivos de I/O
qual o responsável pela interrupção.

A restauração do processo interrompido é obtida a
partir do estado salvo na fase 4.
As opções de reexecutar completa ou parcialmente as instruções
referem-se às instruções que deveriam estar completamente
não executadas, mas que no momento da interrupção
já haviam progredido de nível no pipeline. Na reexecução
completa, todas instruções são exeucutadas a partir
do início do pipeline. Em uma reexecução parcial,
essas instruções retornam um número definido de estágios
do pipeline (retorno de estágios atômico) ou têm
seu clock reduzido em algumas unidades de tempo de execução(retorno
de estágios parcial). Essa útima alternativa apenas pode
ser executada em pipelines onde certos estágios duram mais
do que um ciclo de clock para terminar.
Para continuar a execução, o trabalho executado anteriormente
deve ser refeito. Existem dois métodos para tal: através
de um processador auxiliar que trata as interrupções enquanto
o processador principal pára a execução, e reinicia
após o tratamento. Outro método considera que o estado salvo
na fase 3 está tão completo que nenhum trabalho deve ser
refeito.

O tratamento de interrupções representa uma estratégia
essencial para o aumento do desempenho em sistemas que utilizam pipeline
e arquiteturas superescalares. O tratamento adequado a cada situação
de interrupção depende muito da estratégia empregada,
dos objetivos, e recursos disponíveis, mas sobretudo, do contexto
das interrupções.
As diversas fases do tratamento são interdependentes, e freqüentemente
os sistemas comerciais utilizam diversas técnicas, de acordo com
as exigências de cada interrupção. Assim, apesar da
taxonomia definida por [WC95], não há a fiel obediência
a determinado método no projeto de um processador, e sim a escolha
da melhor forma de tratar as interrupções. Por isso, não
há consenso nem padronização entre a indústria
de processadores, que busca sempre garantir equilibrar desempenho máximo
com custo reduzido.
Uma tendência, registrada entre os processadores, é o de oferecer
ao programador a escolha final: alto desempenho ou garantias absolutas.
Para isso, os sistemas apresentam instruções imprecisas,
mas que podem ser garantidas através do uso de instruções
especiais, que obrigam o processador a tratar as instruções
de forma seqüencial.
[FER98] FERNANDES, E.S.T. Paralelismo a Nível de Instrução e o Custo de Desvios. 11ª Escola de Computação. Rio de Janeiro, 1998.
[WC95] WALKER, Wade, CRAGON, Harvey G. Interrupt Processing in Concurrent Processors. IEEE Computer, pg. 36-45, Junho 1995.
[SP88] SMITH, James E., PLESZKUN, Andrew E. Implementing Precise Interrupts in Pipelined Processors. IEEE Transactions on Computers, Vol. 37, No. 5, Maio 1988.