Par exemple, l'idée est d'étudier uniquement le problème
à l'état stationnaire et le considérer comme un problème
d'algèbre linéaire.
On étudie donc l'équation
On s'intéresse comme dans d'autres méthodes à une récompense
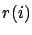
calculée sur la distribution stationnaire
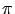
.
Cette approche numérique a été proposée par Courtois et Semal
puis a été étendue
par de nombreux auteurs.
On cherche à borner
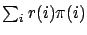
sans connaitre la
distribution
.
La première hypothèse est que nous pouvons encadrer
:
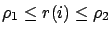
pour tout
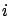
.
On divise l'espace d'états de la chaîne en deux composantes 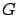 et
et 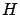 .
contient les états utiles pour le calcul de la récompense
alors que ne contient que des états de très faibles probabilités, ce qui
permet d'avoir une borne efficace.
Soit R la récompense que l'on cherche à obtenir et soit
.
contient les états utiles pour le calcul de la récompense
alors que ne contient que des états de très faibles probabilités, ce qui
permet d'avoir une borne efficace.
Soit R la récompense que l'on cherche à obtenir et soit 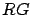 et
et
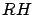 les récompense conditionnelles sachant que l'on est dans un
état de ou de . On a :
les récompense conditionnelles sachant que l'on est dans un
état de ou de . On a :
On élimine grâce à l'encadrement sur les récompense
et on note que
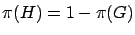 pour obtenir une formule
générale d'encadrement :
pour obtenir une formule
générale d'encadrement :
Si on est capable d'obtenir un encadrement de et de 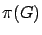 alors on peut obtenir un encadrement sur
alors on peut obtenir un encadrement sur 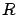 .
Courtois et Semal ont montré que le vecteur
.
Courtois et Semal ont montré que le vecteur 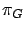 est compris
dans un polyhèdre dont les points extrémaux sont, en général,
plus faciles à
calculer, ce qui donne une borne de la récompense .
L'approche est initialement totalement
algébrique et implique quelques contraintes sur le graphe de la
chaîne. Des extensions et améliorations
proposées, en particulier
par Carrasco puis par
par Rubino et Mahévas, emploient des propriétés sur les
temps d'absorption, de nature plus probabilistes. Il y a les liens
entre ces algorithmes et les approches modulaires, déjŕ explorés par
Buchholz en 2002, et que nous souhaitons approfondir
au sein du projet grâce ŕ une collaboration PRiSM-ARMOR.
est compris
dans un polyhèdre dont les points extrémaux sont, en général,
plus faciles à
calculer, ce qui donne une borne de la récompense .
L'approche est initialement totalement
algébrique et implique quelques contraintes sur le graphe de la
chaîne. Des extensions et améliorations
proposées, en particulier
par Carrasco puis par
par Rubino et Mahévas, emploient des propriétés sur les
temps d'absorption, de nature plus probabilistes. Il y a les liens
entre ces algorithmes et les approches modulaires, déjŕ explorés par
Buchholz en 2002, et que nous souhaitons approfondir
au sein du projet grâce ŕ une collaboration PRiSM-ARMOR.